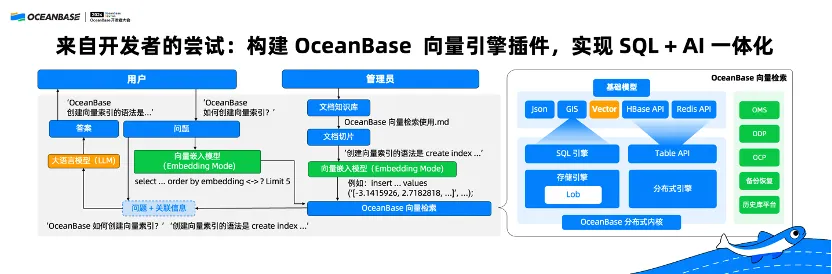
近年来,自然语言处理领域中出现了一种引人注目的模型——ChatGPT。这种基于GPT(Generative Pretrained Transformer)架构的模型,在多轮对话任务中展示了卓越的性能,使其能够产生人类水平的文本,并应用于各种场景,如客服聊天机器人、自动回复系统、交互式娱乐等。本文将深入探讨ChatGPT背后的理论基础,包括其预训练机制、微调过程以及模型架构和优化策略。
一、GPT的基础
要理解ChatGPT,首先需要了解GPT模型。GPT是一种基于Transformer的模型,它使用了自注意力(Self-Attention)机制来捕捉输入数据中的长距离依赖关系。GPT的核心思想是首先在大规模文本数据上进行预训练,学习语言的通用表示,然后在特定任务上进行微调(Fine-tuning),以达到更好的性能。
1.预训练过程
GPT的预训练是无监督学习过程,通常采用语言模型(Language Model, LM)任务。在这个阶段,模型被训练去预测给定文本序列中的下一个单词。这种方法使得模型能够学习到丰富的语言知识和表达能力。
2.微调过程
在预训练完成后,GPT模型可以在特定任务上进行微调。这个过程通常使用监督学习,模型通过少量标注数据学习任务特定知识。在微调过程中,模型的权重会被进一步调整,以适应特定任务的需求。
二、ChatGPT的架构
ChatGPT的架构是构建在原始GPT模型之上的,为了适应复杂的对话环境,它引入了多个关键组件和策略,以便更好地理解和生成自然语言对话。下面我们将深入探讨这些组件和策略。
1.输入表示
ChatGPT和GPT一样,使用了位置编码(Positional Encoding)和分词(Tokenization)机制来表示输入文本。这种表示方法允许模型理解单词顺序和文本的结构。对于对话任务,输入通常是一个由对话历史中的交替发言组成的序列。每个对话片段前通常会添加特殊的分隔符,以帮助模型区分对话中的不同说话者。
2.上下文编码
为了处理多轮对话,ChatGPT必须考虑到之前的交流信息。这是通过在模型架构中集成一个能够处理长序列的上下文编码器实现的。这个编码器可以是传统的Transformer模型,也可以是为长序列优化的变体,例如Sparse Transformer或者Reformer等。
3.注意力机制
自注意力机制是ChatGPT的核心组成部分,它允许模型在生成回复时关注到对话历史中的相关部分。这一点对于理解参考前文的回答或者主题转换等对话现象至关重要。
4.状态跟踪
状态跟踪是对话系统中的一个重要组件,特别是在需要理解和回忆对话历史中的信息时。ChatGPT通过内部的隐状态来编码和追踪对话的状态,这些隐状态可以是显式的键值对存储,也可以是模型隐层激活值的一种形式,使得模型在连贯性上有更好的表现。
5.对话行为建模
在生成回答时,ChatGPT不仅仅是简单地生成下一个可能的单词,它还会模仿人类在对话中的行为模式。这包括提问、回答、陈述、改变话题等复杂的对话动作。为了实现这一点,模型需要预测对话中的行为类型,这通常需要在预训练过程中包含对话行动分类任务。
6.细粒度控制
为了提高对话生成的灵活性和可控性,ChatGPT也可能包含细粒度控制机制,例如情感倾向、话题偏好、语言风格等。这通常通过为模型输入添加额外的控制信号或者进行条件生成来实现。
7.优化与正则化
由于ChatGPT可能有数十亿甚至数百亿的参数,它使用了复杂的优化算法和正则化技术来防止过拟合,并确保训练过程的稳定性。这可能包括使用Adam或LAMB这样的先进优化器,以及在损失函数中加入L1和L2正则化项。
8.解码算法
生成文本时,模型需要采用合适的解码算法来从潜在的无数可能回答中选择一个。常见的方法包括贪心解码、集束搜索(Beam Search)和随机采样(如Top-K采样)等。每种方法在多样性和确定性之间提供了不同的平衡,而ChatGPT可以根据应用场景调整这些参数。
总体来说,ChatGPT的架构是对传统GPT的一个扩展和优化,它特别针对对话场景进行了设计。这些改进使得ChatGPT不仅能够生成流畅和连贯的文本,还能够在复杂的多轮对话中维持一致性和逻辑性。
三、训练与优化策略
训练一个像ChatGPT这样的大规模语言模型涉及到了多个步骤,每一步都需要精心的策略和优化来确保模型的效果和效率。以下是ChatGPT训练和优化过程中的重要组成部分。
1.预训练
预训练是训练ChatGPT的第一步。在这个阶段,模型使用了大量未标记的文本数据来学习语言的基本规律。预训练的目标是使模型能够理解和生成语言,并且掌握广泛的知识。
- 无监督学习任务: 通常,预训练涉及到使用自监督学习任务,如Masked Language Model(MLM)任务,它要求模型预测在输入序列中被随机屏蔽掉的单词。
- 数据清洗与处理: 为了提高预训练的效果,输入数据需要经过清洗和处理,移除噪音,如无效字符、过长的序列等。
- 批量训练(Mini-batch Training): 由于模型的参数量通常非常大,使用小批量数据进行梯度更新是实现有效训练的关键。
- 优化算法: 使用高效的优化算法,如AdamW或者LAMB,能够帮助模型更快地收敛,并提供稳定的梯度更新。
2.微调
在预训练完成后,ChatGPT需要通过微调(Fine-tuning)来适应特定的对话任务。
- 监督学习任务: 微调过程通常使用有标签的对话数据,它要求模型根据给定的对话上下文生成下一句话。
- 任务特定的数据: 微调阶段需要任务特定的数据集,这样模型才能学习到如何针对特定场景生成回复。
- 学习率调度: 为了保留预训练期间学到的知识,微调通常需要一个更小的学习率或者使用学习率衰减策略。
- 正则化方法: 防止过拟合的方法,如dropout和权重衰减,对于微调阶段保持模型的泛化能力同样重要。
3.负样本挖掘
为了提高模型在对话中的适应能力和鲁棒性,可以在训练中引入负样本挖掘机制。
- 对比学习: 通过构造负样本和正样本对,鼓励模型学习区分好的和不好的回答。
- 硬负样本挖掘: 选择或生成与正样本相似但不正确的回答,帮助模型更好地理解对话的细微差异。
4.模型正则化与泛化
为了确保模型能够泛化到未见过的对话,应用一系列正则化技术是必要的。
- 数据增强: 利用数据增强技术,如回译(Back-translation)、同义词替换等,扩展训练数据,提高模型的泛化能力。
- Dropout: 在训练过程中随机"丢弃"神经网络中的一部分连接,以防止模型对特定的训练样本过拟合。
- 早停法(Early Stopping): 监测验证集上的性能,当性能不再提升时停止训练,以防止过拟合。
5.对抗训练
对抗训练是提高模型稳定性的一种技术,它通过向模型输入添加微小的扰动来模拟潜在的攻击或误差。
- 对抗样本生成: 利用生成对抗网络(GAN)或其他对抗攻击手段生成对抗样本。
- 对抗训练循环: 在训练中周期性地使用对抗样本来提高模型对抗此类扰动的鲁棒性。
6.评估与调优
模型在训练过程中的性能需要持续评估,并根据评估结果进行调优。
- 自动评估指标: 使用BLEU、ROUGE或METEOR等自动评估指标来快速评估模型生成文本的质量。
- 人工评估: 虽然自动评估指标有其便利之处,但对于对话模型来说,最终还需要人工评估来确定模型的实际效果,特别是它的连贯性、逻辑性和适应性。
- 超参数优化: 根据评估结果,可以进行超参数搜索,如调整学习率、批次大小、解码策略等,以提高模型的性能。
训练和优化一个像ChatGPT这样的语言模型是一项复杂的任务,它涉及到了从数据预处理到模型架构设计,再到训练策略和评估的各个方面。成功的训练不仅需要高效的算法和技巧,还需要大量的计算资源和精细的调优。通过这些策略和优化方法的应用,ChatGPT能够在复杂的多轮对话中提供高质量的生成文本。
四、结论
ChatGPT作为一种基于Transformer的对话模型,继承了GPT强大的语言生成和理解能力,在处理复杂的多轮对话任务中显示出了显著的优势。通过专门的预训练和微调过程,以及针对性的架构和优化策略,ChatGPT能够在各种对话系统中提供高质量的自然语言交互体验。随着深度学习技术的不断发展,我们可以预见,ChatGPT及其衍生模型将继续推动自然语言处理领域的进步,为人机交互带来更多的可能性。